Practical Issues in Neural Network Training
In spite of the formidable reputation of neural networks as universal function approximators , considerable challenges remain with respect to actually training neural networks to provide this level of performance. These challenges are primarily related to several practical problems
associated with training, the most important one of which is
overfitting.
The Problem of Overfitting
The problem of overfitting refers to the fact that fitting a model to a particular training data set does not guarantee that it will provide good prediction performance on unseen test data, even if the model predicts the targets
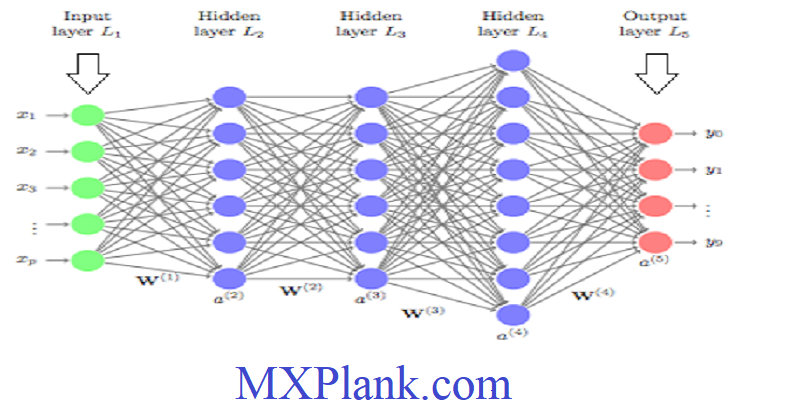
on the training data perfectly. In other words , there is always a gap between the training and test data performance, which is particularly large when the models are complex and the data set is small. In order to understand this point, consider a simple single-layer neural network on a data set with five attributes, where we use the identity activation to learn a real-valued target variable. This architecture is almost identical to that of Figure1.3, except that the identity activation function is used in order to predict a real-valued target.
Therefore, the network tries to learn the following function:

Consider a situation in which the observed target value is real and is always twice the value of the first attribute, whereas other attributes are completely unrelated to the target. However, we have only four training instances, which is one less than the number of features (free parameters). For example, the training instances could be as follows:
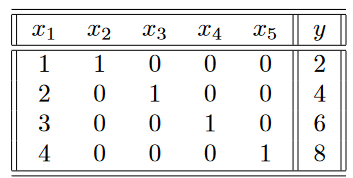
The correct parameter vector in this case is W̄=[2,0,0,0,0] based on the known relationship between the first feature and target. The training data also provides zero error with this solution, although the relationship needs to be
learned from the given instances since it is not given to us a priori. However, the problem is that the number of training points is fewer than the number of parameters and it is possible to find an infinite numberof solutions with zero error. For example, the parameter set [0,2,4,6,8] also provides zero error on the training data.
However, if we used this solution on unseen test data, it is likely to provide very poor performance because the learned parameters are spuriously inferred and are unlikely to
generalize well to new points in which the target is twice the first at-tribute (and other attributes are random). This type of spurious inference is caused by the paucity of training data, where random nuances are encoded into the model. As a result,the solution does not generalize well to unseen test data. This situation is almost similar to learning by rote, which is highly predictive for training data but not predictive for unseen test data.
Increasing the number of training instances improves the generalization power of the model, whereas increasing the complexity of the model reduces its generalization power. At the same time, when a lot of training data is available, an overly simple modelis unlikely to capture complex relationships between the features and target. A good rule of thumb is that the total number of training data points should be at least 2 to 3 times larger than the number of parameters in the neural network, although the precise numberof data instances depends on the specific model at hand. In general, models with a larger number of parameters are said to have
high capacity, and they require a larger amount of data in order to gain generalization power to unseen test data.
The notion of overfitting is often understood in the trade-off between
bias and variance in machine learning. The key
take-away from the notion of bias-variance trade-off is that one does not always win with more powerful (i.e.,
less biased) models when working with limited training data, because of the higher
variance of these models. For example, if we change the training data in the table above to a different set of four points, we are likely to learn a completely different setof parameters (from the random nuances of those points). This new model is likely to yield a completely different prediction
on the same test instance as compared to the predictions using the first training data set. This type of variation in the prediction of the same test instance using different training data sets is a manifestation of
model variance,which also adds to the error of the model; after all, both predictions of the same test instance could not possibly be correct.
More complex models have the drawback of seeing spurious patternsin random nuances, especially when the training data are insufficient. One must be careful to pick an optimum point when deciding the complexity of the model. These notions are described in detail in the coming posts.Neural networks have always been known to theoretically be powerful enough to approximate any function. However, the lack of data availability can result in poor performance; this is one of the reasons that neural networks only recently achieved prominence.
The greater availability of data has revealed the advantages of neural networks over traditional machine learning . In general, neural networks require careful design to minimize the harmful effects of overfitting, even when a large amount of data is available. This section provides an overview of some of the design methods used to mitigate
the impact of overfitting.